离散化的本质就是映射,专门用于处理数据的值域比较大,个数比较少的情况,这时候我们的做法就是离散化:将这些间隔很大的点,映射到相邻的数组元素中,减少对空间的需求,也减少计算量。
离散化
- 值的范围比较大
- 值的个数比较少
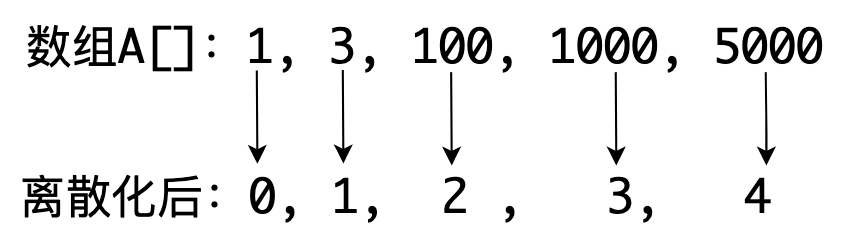
这里可能会疑惑这和哈希有什么区别?
- 哈希表不能像离散化那样缩小数组的空间
核心问题
- 可能存在重复,需要去重
vector<int> A;
sort(A.begin(), A.end()); // 排序
A.erase(unique(A.begin(), A.end()), A.end()); // 去除重复元素
- 如何计算离散化后的值? ==> 二分
// 二分求出x对应离散化的值
int find(int x) {
int l = 0, r = A.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (A[mid] >= x)
r = mid;
l = mid + 1;
}
// 目的为了映射到 1 ~ n
return r + 1;
}
区间和
假定有一个无限长的数轴,数轴上每个坐标上的数都是0。现在,我们首先进行 n 次操作,每次操作将某一位置x上的数加c。接下来,进行 m 次询问,每个询问包含两个整数l和r,你需要求出在区间[l, r]之间的所有数的和。
输入格式
第一行包含两个整数n和m。接下来 n 行,每行包含两个整数x和c。再接下里 m 行,每行包含两个整数l和r。
输出格式
共m行,每行输出一个询问中所求的区间内数字和。
数据范围
输入样例:
3 3
1 2
3 6
7 5
1 3
4 6
7 8
输出样例:
8
0
5
分析:
- 数据分布在,加数据的次数和查询的次数所涉及的数据不超过,离散化处理
- 开辟额外数组存放所以要访问的数组下标,然后进行离散化
- 要访问该下标的时候,根据映射关系函数去访问离散化后的数组对应的值
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> PII;
const int N = 300010;
int n, m;
int a[N], s[N];
vector<PII> add, query;
// 存放需要进行离散化的数据
vector<int> alls;
int find(int x) {
int l = 0, r = alls.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (alls[mid] >= x)
r = mid;
else
l = mid + 1;
}
// 映射到 1 ~ n
return r + 1;
}
int main() {
cin >> n >> m;
for (int i = 0; i < n; i++) {
int x, c;
cin >> x >> c;
// 表示要在x的位置加上c
add.push_back({x, c});
// 存下要进行离散化处理的元素
alls.push_back(x);
}
for (int i = 0; i < m; i++) {
int l, r;
cin >> l >> r;
query.push_back({l, r});
alls.push_back(l);
alls.push_back(r);
}
// 去重
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
for (auto item : add) {
// 找到离散化的位置
int x = find(item.first);
a[x] += item.second;
}
// 预处理前缀和
for (int i = 1; i <= alls.size(); i++)
s[i] = s[i - 1] + a[i];
for (auto item : query) {
int l = find(item.first);
int r = find(item.second);
cout << s[r] - s[l - 1] << endl;
}
return 0;
}
