在基础篇中,我们介绍了lambda表达式的使用和四种主要的函数式接口,其实lambda表达式还有很多应用的地方,例如方法引用、集合的forEach操作和强大的Stream流式编程
方法引用与 lambda
-
方法引用可以让我们直接访问类的实例或者方法,在 lambda 只是执行一个方法的时候,就可以不用 lambda 的编写方式,而用方法引用的方式:实例/类::方法。这样不仅代码更加的紧凑,而且可以增加代码的可读性。
-
当我们要传递给lambda体的操作已经有实现的方法了,可以使用方法引用,方法引用可以看做是lambda表达式深层次的表达。
-
要求:实现接口的抽象方法的参数列表和返回值类型,必须与方法引用的方法的参数列表和返回值类型保持一致
::操作符
前两种情况
@Getter
@Setter
@ToString
@AllArgsConstructor
static class User {
private String name;
private Integer age;
}
public static List<User> userList = new ArrayList<>();
static {
userList.add(new User("A", 26));
userList.add(new User("B", 18));
userList.add(new User("C", 23));
userList.add(new User("D", 19));
}
/**
* 测试方法引用
*/
@Test
public void methodRef() {
User[] userArr = new User[userList.size()];
userList.toArray(userArr);
// User::getAge 调用 getAge 方法
Arrays.sort(userArr, Comparator.comparing(User::getAge));
for (User user : userArr)
System.out.println(user);
}
我们得到结果
{ name='B', age='18'}
{ name='D', age='19'}
{ name='C', age='23'}
{ name='A', age='26'}
forEach 与 lambda
带来了新的遍历方式,Java 8 为集合增加了方法,它可以接受函数接口进行操作。下面看一下 的集合遍历方式。
为什么可以进行表达式遍历?
public interface Collection<E> extends Iterable<E> {
}
public interface Iterable<T> {
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}
我们看到集合接口继承了接口,接口中有默认实现方法中需要传入实现这个函数式接口的实现类,那么我们自然可以使用lambda表达式进行集合的遍历
@Test
public void foreachTest() {
List<String> skills = Arrays.asList("Java", "Golang", "C++", "C", "Python");
// 使用 lambda 之前
for (String skill : skills) {
System.out.print(skill + ",");
}
System.out.println();
// 使用 lambda 之后
// 方式1,forEach lambda
skills.forEach((skill) -> System.out.print(skill + ","));
System.out.println();
// 方式2,forEach 方法引用
skills.forEach(System.out::print);
}
我们得到结果如下
Java,Golang,C++,C,Python,
Java,Golang,C++,C,Python,
JavaGolangC++CPython
Stream 与 lambda
使用一种类似用语句从数据库查询数据的直观方式来提供一种对Java集合运算和表达的高阶抽象。可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
得益于的引入,让 Java 8 中的流式操作成为可能,Java 8 提供了类用于获取数据流。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果
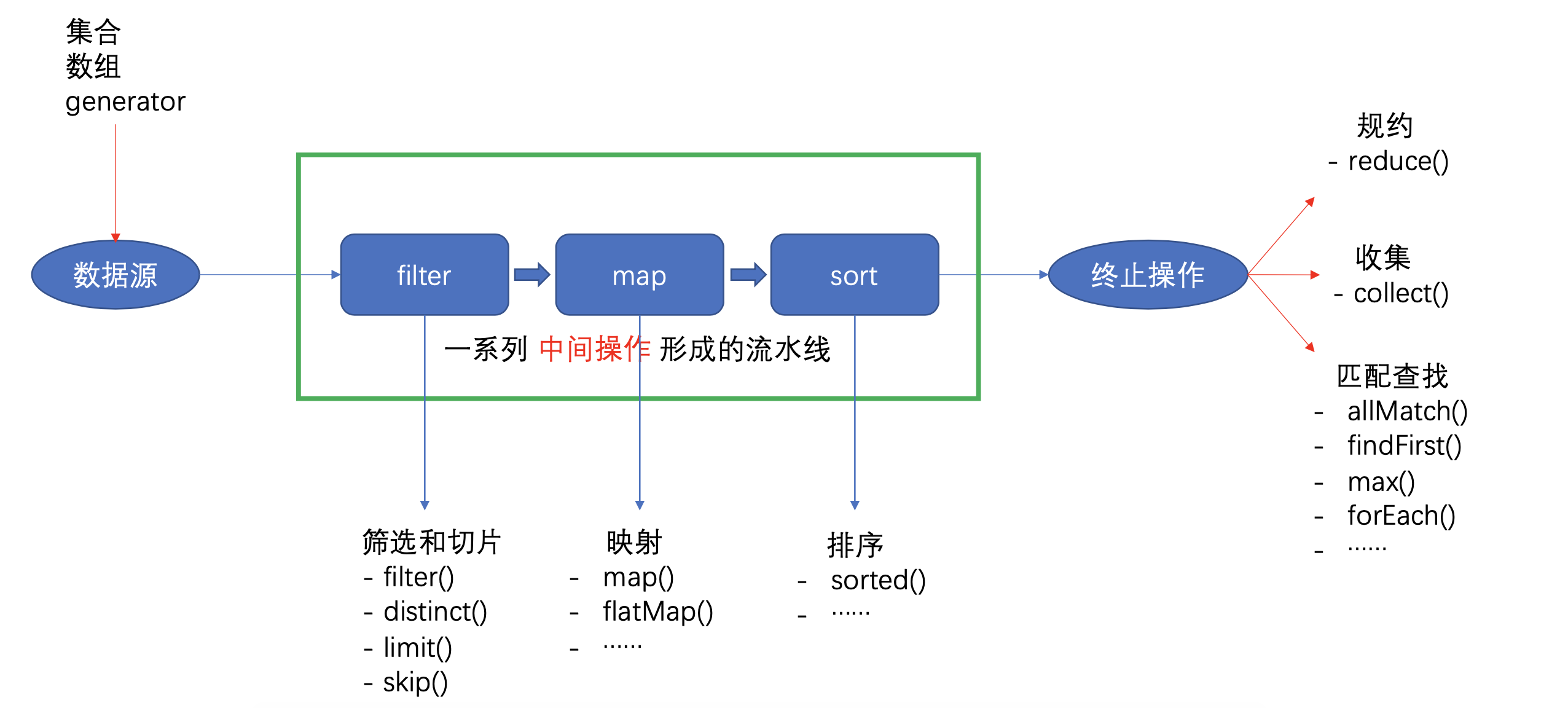
创建Stream
数据源来源可以是集合、数组、、产生器等
/**
* 创建Stream:
* 通过集合
* Stream.of()
* Arrays.stream()
*/
@Test
public void test1() {
List<User> users = UserData.getUsers();
// 通过集合来创建Stream
Stream<User> stream = users.stream();
// 获得并行流
Stream<User> parallelStream = users.parallelStream();
// 通过Stream.of()来创建Stream
Stream<String> stream1 = Stream.of("A", "B","C", "D");
// 通过Arrays.stream()来创建
Integer[] arrs = new Integer[]{1, 2, 3, 4, 5, 6};
Stream<Integer> stream2 = Arrays.stream(arrs);
// 创建无限流
// public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
Stream.iterate(0, t -> t + 2).limit(10).forEach(System.out::println);
System.out.println("----------------");
// public static<T> Stream<T> generate(Supplier<T> s)
Stream.generate(Math::random).limit(10).forEach(System.out::println);
}
中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上出发终止操作。否则中间操作不会执行任何的处理,而在终止操作时一次性全部处理,称为“惰性求值”
筛选和切片
- :接收lambda,从流中排除某些元素
- :筛选,通过流所生成元素的
hashCode()和equals()去除重复元素 - :截断流,使其元素不超过给定数量
- :跳过元素,返回一个扔掉了前
n个元素的流,若流中元素不足n个,则返回一个空流
测试
/**
* 筛选和切片
* limit(), distinct(), filter(), skip()
*/
@Test
public void test2() {
Stream<Integer> stream = Stream.of(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14);
Stream<Integer> newStream = stream.filter(s -> s > 5) // 6 6 7 9 8 10 12 14 14(筛选出 > 5 的元素)
.distinct() // 6 7 9 8 10 12 14 (去重)
.skip(2) // 9 8 10 12 14 (跳过前两个)
.limit(2); // 9 8 (截断前两个)
newStream.forEach(System.out::println); // 终止操作
}
映射
- :接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素
- :接收一个函数作为参数,将流中每个值斗转成另一个流,然后把所有流连成一个流
测试
/**
* 映射map(), flatMap()
*/
@Test
public void test3() {
List<String> list = Arrays.asList("a,b,c", "1,2,3");
// 将每个元素转换成一个新的不带逗号的元素
Stream<String> stream1 = list.stream().map(s -> s.replaceAll(",", ""));
stream1.forEach(System.out::println); // abc 123
System.out.println("--------------");
Stream<String> stream2 = list.stream().flatMap(s -> {
String[] split = s.split(",");
return Arrays.stream(split);
});
stream2.forEach(System.out::println); // a b c 1 2 3
}
排序
- :产生一个新流,其中按自然顺序排序
- :产生一个新流,其中按比较器顺序排序
测试
/**
* 排序sort()
*/
@Test
public void test4() {
List<String> list = Arrays.asList("aa", "ff", "dd");
//String 类自身已实现Compareable接口
list.stream().sorted().forEach(System.out::println);// aa dd ff
User u1 = new User("aa", 10);
User u2 = new User("bb", 20);
User u3 = new User("aa", 30);
User u4 = new User("dd", 40);
List<User> users = Arrays.asList(u1, u2, u3, u4);
//自定义排序:先按姓名升序,姓名相同则按年龄升序
users.stream().sorted((o1, o2) -> {
if (o1.getName().equals(o2.getName()))
return o1.getAge() - o2.getAge();
else
return o1.getName().compareTo(o2.getName());
}).forEach(System.out::println);
}
终止操作
终止操作会从流的流水线生成结果。其结果可以使任何不适流的值,例如,甚至是。并且流进行了终止操作后,不能再次使用
匹配与查找
- :检查是否匹配所有元素
- :检查是否至少匹配一个元素
- :检查是否没有匹配所有元素
- :返回第一个元素
- :返回当前流任意元素
- :返回流中元素的总个数
- :返回流中元素最大值
- :返回流中元素最小值
- :内部迭代
/**
* 匹配和查找
*/
@Test
public void test5() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(e -> e > 10); // false
boolean noneMatch = list.stream().noneMatch(e -> e > 10); // true
boolean anyMatch = list.stream().anyMatch(e -> e > 4); // true
Integer findFirst = list.stream().findFirst().get(); // 1
Integer findAny = list.stream().findAny().get(); // 1
long count = list.stream().count(); //5
Integer max = list.stream().max(Integer::compareTo).get(); //5
Integer min = list.stream().min(Integer::compareTo).get(); //1
list.stream().forEach(System.out::println); // 1 2 3 4 5
}
规约
首先我们看一下和的接口信息
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
...
}
@FunctionalInterface
public interface BiFunction<T, U, R> {
R apply(T t, U u);
...
}
这个接口继承接口,当我们向接口实现类传入一个参数类型为的参数,就相当于我们传入这个接口两个类型都为的参数,返回类型也是,这样就方便我们理解其的下面操作
- :第一次执行时,函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。
- :流程跟上面一样,只是第一次执行时,函数的第一个参数为,而第二个参数为流中的第一个元素。
- :在串行流中,该方法跟第二个方法一样,即第三个参数不会起作用。在并行流中,我们知道流被出多个线程进行执行,此时每个线程的执行流程就跟第二个方法一样,而第三个参数函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法流程进行规约
测试
/**
* 规约reduce()
*/
@Test
public void test6() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Integer reduce1 = list.stream().reduce(0, (t1, t2) -> t1 + t2);
System.out.println("list总和:"+ reduce1); // 15
System.out.println("--------------");
User u1 = new User("aa", 10);
User u2 = new User("bb", 20);
User u3 = new User("aa", 30);
User u4 = new User("dd", 40);
List<User> users = Arrays.asList(u1, u2, u3, u4);
// 计算年龄总和
Optional<Integer> reduce2 = users.stream().map(User::getAge).reduce(Integer::sum);
System.out.println("年龄总和:" + reduce2);
System.out.println("-------------");
Integer reduce3 = list.parallelStream().reduce(0, (x1, x2) -> {
System.out.println("parallelStream accumulator: x1:" + x1 + " x2:" + x2);
return x1 - x2;
}, (x1, x2) -> {
System.out.println("parallelStream combiner: x1:" + x1 + " x2:" + x2);
return x1 * x2;
});
System.out.println(reduce3); // -120
}
收集
- :将流转换为其他形式。接收一个接口的实现,用于中元素做汇总的方法(接口中方法的实现决定了如何对流执行收集的操作:如收集到)
/**
* 收集collect()
*/
@Test
public void test7() {
User s1 = new User("aa", 10);
User s2 = new User("bb", 20);
User s3 = new User("cc", 10);
List<User> list = Arrays.asList(s1, s2, s3);
// 装成list
List<Integer> ageList = list.stream().map(User::getAge).collect(Collectors.toList()); // [10, 20, 10]
System.out.println(ageList); // [10, 20, 10]
// 转成set
Set<Integer> ageSet = list.stream().map(User::getAge).collect(Collectors.toSet());
System.out.println(ageSet); // [20, 10]
// 转成map,注:key不能相同,否则报错
Map<String, Integer> userMap = list.stream().collect(Collectors.toMap(User::getName, User::getAge)); // {cc=10, bb=20, aa=10}
System.out.println(userMap);
}
lambda总结
结合函数接口,方法引用,类型推导以及流式操作,可以让代码变得更加简洁紧凑,也可以借此开发出更加强大且支持并行计算的程序,函数编程也为 Java 带来了新的程序设计方式。但是缺点也很明显,在实际的使用过程中可能会发现调式困难,测试表示的遍历性能并不如的性能高。
